Note: This project was conducted as part of the Conversational AI course taught by Professor Mirco Ravanelli at Concordia University. For further details, insights, and full implementation, please refer to the GitHub repository. The entire workflow and explanations are documented in the notebook located at
_notebooks/Notebook_Growing_Networks.ipynb.
Abstract
In this project, I focused on growing neural networks. I started with a literature review (see at the bottom) to explore different methods to understand when and how to grow a network. I then implemented [Net2Net] to evolve MLP architectures, and compared their performance to those of models trained classically on the MNIST and FashionMNIST datasets. In the first part, I showed that Net2Net allows to transfer knowledge and explore new architectures more quickly, while preserving the initial function, correctly handling batch normalization, and integrating the addition of noise during network expansion. In the second part, I studied the effects of growing during the training phase. Although the benefits are difficult to observe on simple tasks like MNIST, some interesting learning dynamics were highlighted. In the third part, I reimplemented a CTC-based ASR chain with a scalable CRDNN to further analyze the effects of growing a network. While the growth stages work technically, the results remain modest. Overall, this work validates the feasibility of the growing network concept, while highlighting the need for further experimentation on more complex architectures and more realistic tasks to fully assess its impact.
Motivation
Conventional neural networks have a fixed architecture throughout training. In contrast, dynamically growing networks can adapt their structure along the way, allowing you to start with a simple, lighter model and then gradually expand it. This approach offers advantages in terms of both efficiency and regularisation.
This subject is also closely linked to Continual Learning, an area of particular interest to me. Adding new neurons to learn without forgetting old knowledge is a promising way of solving the challenges of stability and plasticity.
Finally, the application to speech, a complex and rich field, allowed me to put into practice the tools I studied in the Conversational AI course, in particular SpeechBrain.
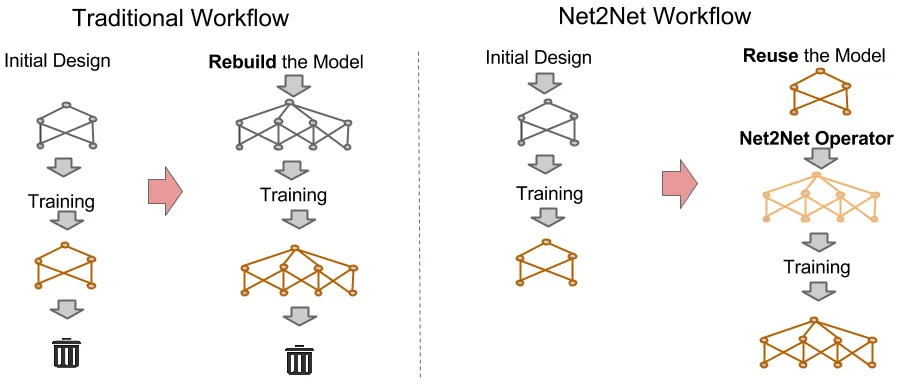 Comparison between a traditional workflow and the Net2Net Workflow; Net2Net reuses information from an already trained model to speed up the training of a new bigger model. Extracted from [1]
Comparison between a traditional workflow and the Net2Net Workflow; Net2Net reuses information from an already trained model to speed up the training of a new bigger model. Extracted from [1]
Experiments
To evaluate the benefits and limitations of growing neural networks, I conducted two sets of experiments: one on vision datasets (MNIST and FashionMNIST) and another on speech data (TIMIT).
For MNIST and FashionMNIST, I implemented Net2Net growth strategies on MLPs. The experiments included growing the network at different training stages and comparing them with classically trained “young” (small) and “adult” (large) models. Key variables included learning rate, optimizer (Adam/SGD), and the effect of adding noise or batch normalization.
For TIMIT, I re-implemented a CTC-based ASR chain using SpeechBrain and embedded a scalable CRDNN architecture. I evaluated the feasibility and impact of applying growth within this more complex context. Growth steps were manually triggered, and metrics were logged throughout the training process.
All experimental details, growth functions, and training curves are available in the provided notebook for reproducibility and further insight.
Results
On MNIST and FashionMNIST, the grown models reached performance close to the “adult” networks, particularly when using SGD with momentum and proper learning rate decay after each growth step. The function-preserving nature of Net2Net helped ensure smooth transitions during expansion. However, the gains in accuracy compared to training a large model from scratch remained limited on these simple tasks.
On TIMIT, while the growth operations technically worked, the performance improvements were modest. The complexity of the speech recognition task revealed that simple growth strategies might not be sufficient, and more advanced architectural changes or training procedures could be necessary.
Overall, the experiments validated the technical feasibility of growing networks, especially using Net2Net transformations, but also highlighted the need for more realistic scenarios and architectures to fully showcase their potential.
Litterature Review
In this section, I present several papers that I have discovered while exploring the literature on growing networks. I am aware that I am not covering all that has been explored in the past in relation to the topics I am addressing in this project.
I may have missed important papers or ideas in the following but tried my best to group them to cover as much as possible.
This might more be seen as a context fundation rather than an exhaustive study.
Growing Networks in Continual Learning
Key Papers:
-
Net2Net: Accelerating Learning via Knowledge Transfer (Chen et al., 2016) [1]:
In this paper, the author introduces two methods to grow a network in both width and depth. It avoids a model to retrain from scratch when growing by transferring knowledge in a way that preserve the function. It can significantly reduce training time for bigger models. -
Progressive Neural Networks (PNN) (Rusu et al., 2016) [2]:
This architecture is an example of the link between continual learning and growing networks. When it grows for a new task, the model adds a new neural “column”. This is done while freezing the rest of the networks. This way, the new networks is immune to forgetting and only the new weights are used for plasticity using knowledge transfer from earlier tasks. It works well, but comes at the cost of growing the networks linearly with the number of tasks which makes it a little limiting in a lifelong learning context. -
Lifelong Learning with Dynamically Expandable Networks (DEN) (Yoon et al., 2018) [3]:
In this paper, the author proposes an architecture that decides it’s capacity on the fly when learning different tasks. DEN architecture knows when and how to retrains weights and add neurons if necessary. This avoids growing when unecessary such as when the tasks are close together and the previous neurons can handle it. It uses strategies like splitting and duplicating neurons and mark each neuron with a birth date. It allows to grow only with the required number of neurons per task. -
Compacting, Picking and Growing for Unforgetting Continual Learning (CPG) (Hung et al., 2019) [4]:
CPG architectures is a combination of method. It first relies on deep model compression via weights pruning (Compacting), critical weights solutions (Picking) and selective progressive net extension (Growing). It can be seen as a counter to the fast growing limitation of architecture like PNN [2]. Growing is not mandatory in CPG, if the released weights are sufficient, this is acceptable. -
Firefly Neural Architecture Descent: a General Approach for Growing Neural Networks (Wu et al., 2020) [5]:
This paper from NeurIPS introduces a general approach to grow a network. What makes it special is its ability to assess a wider or deeper set of neighbouring architectures, measuring their potential impact on loss. It has great results in continual learning and leads to models that are often smaller but with a high accuracy.
Overview of techniques to grow a network
The main objective when a model is grown is to increase its capacity. In in this part, we aim to compare different methods from the litterature:
-
Add Modules or Networks:
This growing technique is what I would like to call the safe one. For a new task, an entire module or even a network is added. It can be associated to methods such as PNN [2], where an entire new network called “column” is added for each new task and linked to the rest of the architecture with lateral connections. Multi-expert methods like Expert Gate [6] are also a good example where a new expert network is created for a new task and the model learns to route the inputs between these experts. The big advantage of these methods is that they are immune to forgetting and separate tasks well. However, this is often at the cost of a size that grows very quickly, making them useless for long sequences of stains. -
Add or Expand Layers:
A second technique seen in the litterature is to grow inside the network. This means that the expansion will be achieved through the incorporation of additional neurons into a specific layer or the augmentation of the number of layers. A really evident example here is the Net2Net method [1]. When using the Net2WiderNet transformation, a new bigger network is instantianted performing the same function as the previous one (function-preserving) by replicating neurons/filters from the original model. For Net2DeeperNet, it is the same idea but this time, the layers are replicated. DEN [3] should also be mentionned here as it grows within existing layers, adding the needed number of neurons to perform the task if not possible with the already existing one. CPG [4] also uses a Net2Wider approach to grow the model. It is not stated in the paper directly, but it can be seen in the implementation. The main difference is in the heuristics where CPG might decide not to grow but to free up space in its current architecture.
The major objective here is to grow smoothly and augment the model capacity without ruining all the previous efforts. The main challenge here is to know when and how much to grow. It is a central question regarding growing networks that I will try to explain a bit further below. -
Architecture Search:
Approach like Firefly [5] sees the whole structure as something that can be optimized or learned. It uses algorithm to search for an optimal model during training. For Firefly, it is a gradient-based approach that tries different configurations such as wider, deeper, etc. It evaluates it on the objective and choose the one that has the best results. These techniques are designed to find the most efficient architectures for a model but it can lead to very heavy computations. Other methods such as AdaNet [7] or BNS [8] are linked to that type of model expansion. The latter uses RL to search the best continual learner by testing architectures. However, I couldn’t find time to read more on their respective paper. -
Grow with regularization:
There are some methods that we already discussed that rely on regularization to grow. DEN is the perfect example where the weights of the previous task are reduced via sparse-regularization. The sparsity induced by the L1/L2 regularization helps isolate the weights that are really necessary. The rest can be reused or expanded for future tasks if the loss cannot be reduced. It seems that CPG also is based on regularization when learning the binary mask for weight consolidation but again, it is not clearly stated. These methods combining regularization to prune the networks and expansion are really interesting as they yield a fully “alive” network. It is smarter than just copying the whole network, and it keeps the model small enough for lots of other tasks. It works really well, according to the research papers.
Overview of Criterias for Network Growth
Now that we have a pretty clear idea of how to make the network grow, we need to look at the second most important question: when should it grow? Let’s again look at the litterature:
-
Task-Aware Expansion:
The most natural way of deciding when to grow a network in a continuous learning context is when a new task arrives. It means new data or a change in the objective. This change is seen as a trigger by the model to consider growing. For example, PNN [2]architecture grows the model by adding a “column” every time that a task arrives. Methods such as CPG [4]or DEN [3] use this trigger to see if they need to expand and then apply their rules to see if an expansion is needed based on the current model. This is called task-aware expansion. This method makes sense but requires comprehension of the tasks and their respective commencement dates. -
Performance-Based Expansion:
A good way to decide when to grow is by monitoring the performance. By tracking the loss or the accuracy we can identify potential plateaus or accuracy drops that would indicate the need for more capacity. This introduces the concept of task-free or task-agnostic CL. The architecture should detect alone when it needs to expand. Method like CPG [4], even if the evaluation algorithm is triggered by each task, check if the pruned and retrained model meets a certain preset performance objective. If not, it expand and repeat the process until the target performance is reached. A growth criterion such as this requires a threshold to be defined. There are several ways of defining this threshold, such as cross-validation or simply zero-forgetting. In the Firefly [5] method, this is automated. It constantly evaluates the possibilities for expansion and chooses the one that has the best effect on loss by enlarging when the error can be reduced. -
Change in distribution:
Another interesting approach especially in the task-free scenario is to detect when data has changed enough to justify a growth. To do so, the input data is scanned and if it diverges sufficiently then this is taken as an indicator of possible expansion. For example, in the SEDEM [9] method, the model use a “diversity measure” between experts to see if a new one is needed. In other words, the experts periodically agree on a common representation of new samples; if the entries from a new batch diverge too much from this, then it’s time to grow. This method is strong because if the data distribution are different but similar, the network might be able to handle it without any need to grow.
It is likely that many relevant methods may exist beyond the scope of my current exploration.
References
[1] T. Chen, I. Goodfellow, and J. Shlens, “Net2Net: Accelerating Learning via Knowledge Transfer,” Apr. 23, 2016, arXiv: arXiv:1511.05641. doi: 10.48550/arXiv.1511.05641.
[2] A. A. Rusu et al., “Progressive Neural Networks,” Oct. 22, 2022, arXiv: arXiv:1606.04671. doi: 10.48550/arXiv.1606.04671.
[3] J. Yoon, E. Yang, J. Lee, and S. J. Hwang, “Lifelong Learning with Dynamically Expandable Networks,” Jun. 11, 2018, arXiv: arXiv:1708.01547. doi: 10.48550/arXiv.1708.01547.
[4] S. C. Y. Hung, C.-H. Tu, C.-E. Wu, C.-H. Chen, Y.-M. Chan, and C.-S. Chen, “Compacting, Picking and Growing for Unforgetting Continual Learning,” Oct. 30, 2019, arXiv: arXiv:1910.06562. doi: 10.48550/arXiv.1910.06562.
[5] L. Wu, B. Liu, P. Stone, and Q. Liu, “Firefly Neural Architecture Descent: a General Approach for Growing Neural Networks,” Jun. 21, 2021, arXiv: arXiv:2102.08574. doi: 10.48550/arXiv.2102.08574.
[6] R. Aljundi, P. Chakravarty, and T. Tuytelaars, “Expert Gate: Lifelong Learning with a Network of Experts,” Apr. 19, 2017, arXiv: arXiv:1611.06194. doi: 10.48550/arXiv.1611.06194.
[7] C. Cortes, X. Gonzalvo, V. Kuznetsov, M. Mohri, and S. Yang, “AdaNet: Adaptive Structural Learning of Artificial Neural Networks,” in Proceedings of the 34th International Conference on Machine Learning, PMLR, Jul. 2017, pp. 874–883. Accessed: Mar. 27, 2025. [Online]. Available: https://proceedings.mlr.press/v70/cortes17a.html
[8] Q. Qin, W. Hu, H. Peng, D. Zhao, and B. Liu, “BNS: Building Network Structures Dynamically for Continual Learning,” in Advances in Neural Information Processing Systems, Curran Associates, Inc., 2021, pp. 20608–20620. Accessed: Apr. 22, 2025. [Online]. Available: https://proceedings.neurips.cc/paper/2021/hash/ac64504cc249b070772848642cffe6ff-Abstract.html
[9] F. Ye and A. G. Bors, “Self-Evolved Dynamic Expansion Model for Task-Free Continual Learning,” in 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France: IEEE, Oct. 2023, pp. 22045–22055. doi: 10.1109/ICCV51070.2023.02020.
[10] D. Slater, Net2Net TensorFlow MNIST example, GitHub repository, 2016. [Online]. Available: https://github.com/DanielSlater/Net2Net
[11] Garofolo, John S., et al. TIMIT Acoustic-Phonetic Continuous Speech Corpus LDC93S1. Web Download. Philadelphia: Linguistic Data Consortium, 1993.
[12] M. Ravanelli, T. Parcollet, A. Moumen, S. de Langen, C. Subakan, P. Plantinga, Y. Wang, P. Mousavi, L. Della Libera, A. Ploujnikov, F. Paissan, D. Borra, S. Zaiem, Z. Zhao, S. Zhang, G. Karakasidis, S.-L. Yeh, P. Champion, A. Rouhe, R. Braun, F. Mai, J. Zuluaga-Gomez, S. M. Mousavi, A. Nautsch, X. Liu, S. Sagar, J. Duret, S. Mdhaffar, G. Laperrière, M. Rouvier, R. De Mori, and Y. Esteve, “Open-Source Conversational AI with SpeechBrain 1.0,” arXiv preprint arXiv:2407.00463, 2024. [Online]. Available: https://arxiv.org/abs/2407.00463
[13] M. Ravanelli, T. Parcollet, P. Plantinga, A. Rouhe, S. Cornell, L. Lugosch, C. Subakan, N. Dawalatabad, H. Abdelwahab, J. Zhong, J.-C. Chou, S.-L. Yeh, S.-W. Fu, C.-F. Liao, E. Rastorgueva, F. Grondin, W. Aris, H. Na, Y. Gao, R. De Mori, and Y. Bengio, “SpeechBrain: A General-Purpose Speech Toolkit,” arXiv preprint arXiv:2106.04624, 2021. [Online]. Available: https://arxiv.org/abs/2106.04624