Abstract
This work is an attempt to outperform the student-teacher feature pyramid matching
for anomaly detection paper [Wang et. al.], we address it’s limitation by integrating autoencoders
into the student-teacher framework. This integration is done to better
capture anomaly features to enable effective anomaly scoring. Our proposed approach
aims to achieve results comparable to or better than the baseline framework
on the MVTec anomaly detection dataset. The following paper accompanies the summary on this page in greater detail.

Note: This paper was not intended for publication but was created as part of a class project in a Machine Learning course. Nevertheless, it demonstrates my ability to effectively present results and articulate insights clearly and professionally.
Context
Anomaly detection plays a critical role in various applications such as industrial quality control and medical imaging. It involves identifying data points or patterns that deviate significantly from expected behavior. The key challenge lies in the limited availability of labeled anomaly data, which necessitates one-class learning techniques.
Building upon the Student-Teacher Feature Pyramid Matching (ST-FPM) framework, this project introduces auto-encoders into the pipeline. These additions enhance the reconstruction of anomaly-free distributions, enabling more robust feature extraction and anomaly localization. The improvements aim to maintain or exceed the performance of the original ST-FPM framework on the MVTec Anomaly Detection Dataset.
Methodology
Framework Overview
The ST-FPM framework uses a teacher model (a robust pre-trained network) to guide a student model. The student learns to mimic the teacher’s outputs on normal data. Our contribution integrates auto-encoders at each student layer to refine the reconstruction of feature maps. These auto-encoders are based on a customized U-Net architecture, designed for efficient processing of multi-scale feature maps.
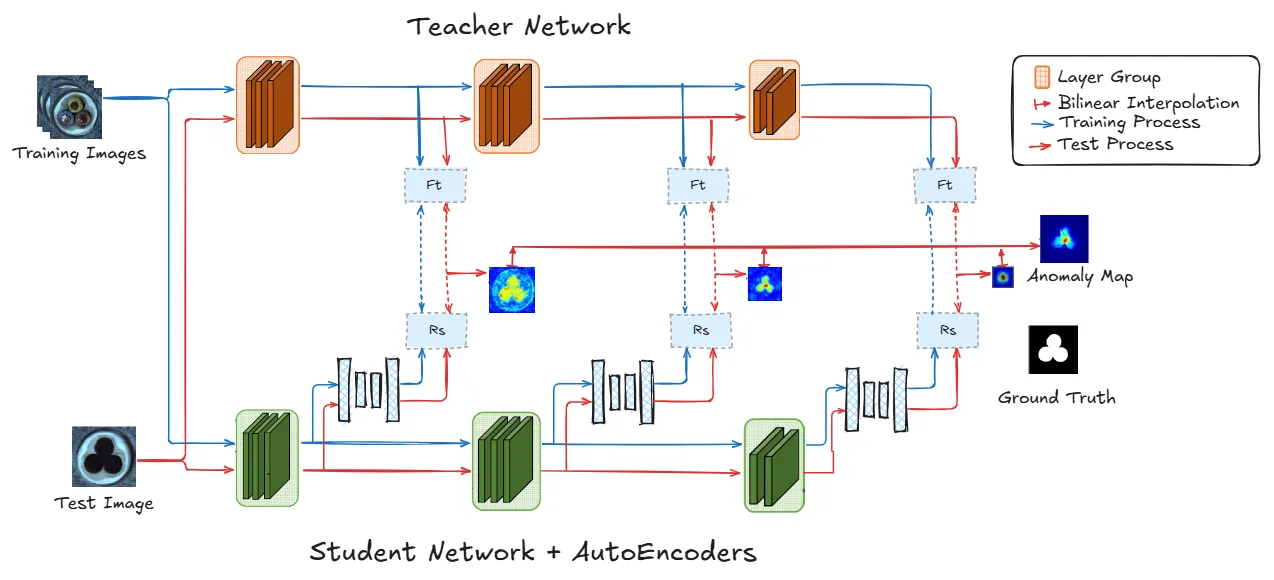 Schematic overview of our extended method. It adds three auto-encoders to the architecture
proposed by Wang et al. to reconstruct the student’s feature maps at each level of the architecture.
Training and testing process is represented as long as the multi-scale anomaly map computation path.
Anomalies are detected in a single forward pass.
Schematic overview of our extended method. It adds three auto-encoders to the architecture
proposed by Wang et al. to reconstruct the student’s feature maps at each level of the architecture.
Training and testing process is represented as long as the multi-scale anomaly map computation path.
Anomalies are detected in a single forward pass.
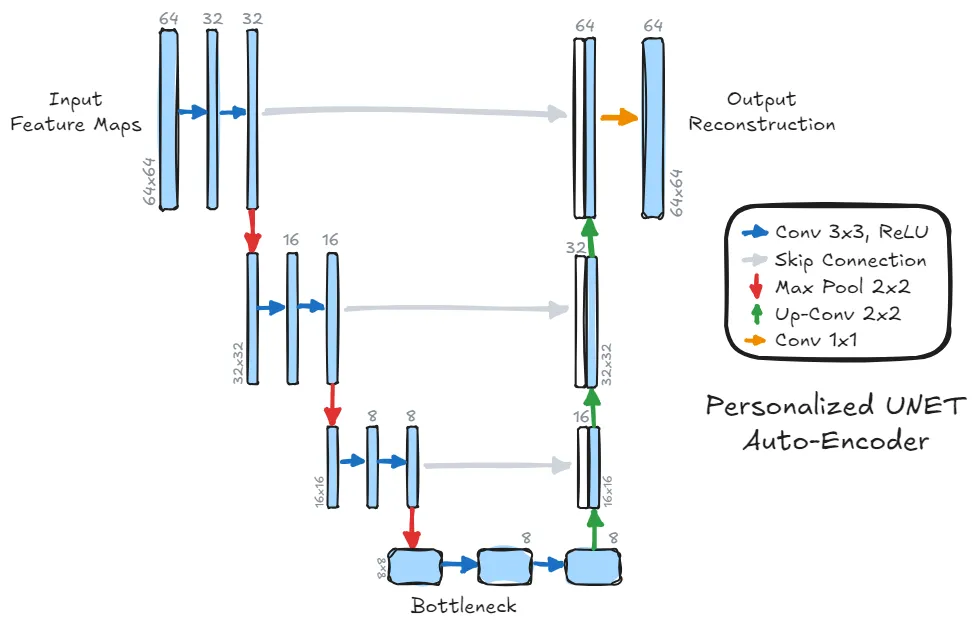 Schematic overview of our personalized U-net architecture. This model represents the
auto-encoder for the first layer of our framework, but the idea is the same for the others. It processes
the feature maps progressively, reducing the resolution by a contraction path to a bottleneck, and then
reconstructing the feature maps to the original resolution and channel depth. Skip connections link
the encoder and decoder and no convolution is applied after the concatenation.
Schematic overview of our personalized U-net architecture. This model represents the
auto-encoder for the first layer of our framework, but the idea is the same for the others. It processes
the feature maps progressively, reducing the resolution by a contraction path to a bottleneck, and then
reconstructing the feature maps to the original resolution and channel depth. Skip connections link
the encoder and decoder and no convolution is applied after the concatenation.
Training Process
-
Pretraining the Auto-Encoders:
- Each auto-encoder is pre-trained to reconstruct feature maps from the teacher model.
- Loss Function: Mean Squared Error (MSE) between the reconstructed and original feature maps.
- Optimizer: Adam with a learning rate of 0.001.
- This ensures the auto-encoders capture normal patterns effectively before being fine-tuned with the student network.
-
Joint Training:
- The complete architecture is trained with two key loss components:
- Reconstruction Loss: Ensures accurate feature map reconstruction from the student’s output.
- Similarity Loss: Measures alignment between the teacher and reconstructed feature maps.
- Gradient clipping and differentiated learning rates are used to stabilize training, with a higher rate for the student network and a lower one for the auto-encoders.
- The complete architecture is trained with two key loss components:
Testing Process
During testing:
- An input image is processed by both the teacher and student models.
- The student’s feature maps are reconstructed by the auto-encoders, and pixel-wise losses are computed.
- A multi-scale anomaly map is generated by aggregating these pixel-wise losses across layers.
- Anomaly scores are evaluated using the AUC-ROC metric, which compares continuous anomaly scores with ground-truth binary labels.
Results
The proposed approach was evaluated on the MVTec Anomaly Detection Dataset, focusing on categories such as “bottles” and “leather.” Results demonstrated:
- Competitive AUC-ROC Scores:
- For “leather,” the Pixel-Level AUC reached 0.9934, while the Image-Level AUC reached 0.9973. We have equalized the performance of the original framework.
- For “bottles,” the Pixel-Level AUC reached 0.9837. It is slightly below the performance of the paper, we explain this by the increased complexity of the bottles in relation to a leather piece, the auto-encoder struggles a bit more.
| Model | Pixel-Level AUC | Image-Level AUC | Paper Results |
|---|---|---|---|
| U-Net on Leather | 0.9934 | 0.9973 | 0.993 |
| U-Net on Bottles | 0.9837 | 1.0000 | 0.998 |
- Improved Visual Anomaly Maps: The integration of auto-encoders results in more defined and accurate anomaly localization compared to the baseline ST-FPM model.
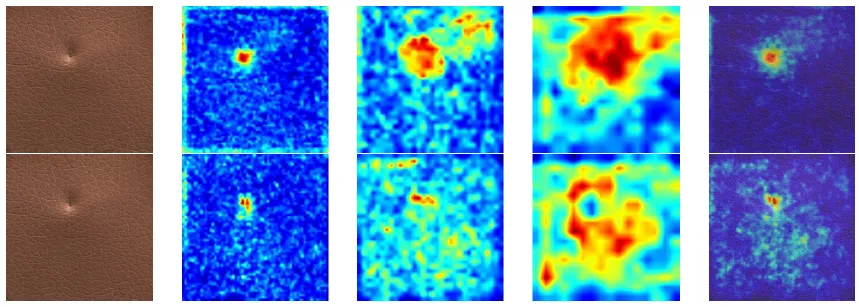 Visual results of our method compared to the classical ST-FPM architecture on a
defective image of a leather shred. The top row is our model. Columns from left to right correspond
to input image, anomaly maps of the three blocks in reverse order (16x16,32x32,64x64) and the
resulting anomaly map superposed on the image.
Visual results of our method compared to the classical ST-FPM architecture on a
defective image of a leather shred. The top row is our model. Columns from left to right correspond
to input image, anomaly maps of the three blocks in reverse order (16x16,32x32,64x64) and the
resulting anomaly map superposed on the image.
These results underscore the partial effectiveness of integrating U-Net auto-encoders, particularly in capturing complex features and highlighting anomalies with precision.
Discussion
This project validates the potential of combining auto-encoders with the ST-FPM framework for anomaly detection. The improvements are notable in terms of visual anomaly maps. However, we need to be cautious and realize that this is not being done for free, but at the cost of a trade-off that needs to be taken seriously. The major compromise here comes from the added complexity. Although the results look promising, they are not enough to definitively justify the increase in complexity in terms of calculation and architecture. Of course, this should not detract from the value of our work, but we would like to point out that we are aware of the potential for unnecessary complexity that would come with this area of improvement. With this project, we immersed ourselves in a more research-oriented approach, learning to juggle implementations, tests, reading, and theoretical understanding as we gradually wrote this paper.
Lessons Learned
- Complexity vs. Performance: While the integration of auto-encoders enhances results, it introduces significant computational costs. This highlights the importance of balancing model complexity with practical feasibility.
- Generalization through Simplification: Our modified U-Net architecture, which omits additional convolutions in the decoding path, performed better here than traditional designs. This demonstrates the value of exploring simpler architectures for specific tasks.
Future Work
To further refine this approach:
- Dynamic Loss Weighting: Introduce adaptive weighting for reconstruction and similarity losses to better balance training objectives.
- Mitigating Boundary Effects: Employ cropping or other techniques to address border artifacts during convolutions.
- Hyperparameter Optimization: Explore different combinations of learning rates, weighting parameters, and auto-encoder architectures for improved performance.
- Expanding Dataset Coverage: Test the model on more diverse datasets to evaluate its generalizability.
For more details, please refer to the accompanying paper